Data Warehouse — Medallion Architecture on Azure SQL

Role:
TSQL
Date:
Winter 2026
A Data Warehouse Two Systems Can Agree On
Every dashboard a business trusts is sitting on top of a quiet assumption: that the numbers underneath it are clean, consistent, and mean what they say. That assumption almost never survives contact with real source systems. In this project, I took two of them — a CRM and an ERP that disagree about customer IDs, spell gender five different ways, and store dates as eight-digit integers — and built a warehouse that turns their raw exports into a star schema an analyst can query without ever thinking about where the data came from. The pattern is the Medallion architecture: Bronze, Silver, Gold. The interesting part isn’t the pattern. It’s everything the data did to fight it.

The architecture
The whole design rests on one rule: each layer has exactly one job and never reaches past it.
Bronze is raw and untyped. Everything lands as NVARCHAR, dates included. Loads are full-refresh — TRUNCATE then BULK INSERT straight from the source CSVs, wrapped in a stored procedure. Bronze makes no decisions and fixes nothing; its only promise is “this is exactly what the source sent us.” That sounds lazy, but it’s the layer that lets me re-run the entire pipeline from a clean slate and reproduce any downstream number, because nothing has been silently overwritten on ingest.
Silver is where the data becomes trustworthy. This is the cleansing and conforming layer: typed columns, parsed dates, expanded codes, deduplicated rows, and — the hard one — natural keys from two systems hammered into a shape where they actually join. Silver still mirrors the source tables one-for-one. It doesn’t model the business yet; it just makes the data correct.
Gold is the business model. A Kimball star schema, exposed as views rather than materialized tables, so the dimensions and facts always reflect the current Silver state with no extra refresh step to forget. This is the only layer a BI tool or analyst ever touches.
Why this pattern instead of one big cleaning script? Because it separates concerns you’d otherwise tangle together — ingestion, correctness, and modeling each fail for different reasons, and when something breaks I want to know which of the three it was. Bronze isolates source problems. Silver isolates data-quality problems. Gold isolates modeling problems. Debugging a warehouse is mostly about knowing which layer to look in.
The hard parts
None of the difficulty was in the architecture. All of it was in the data.
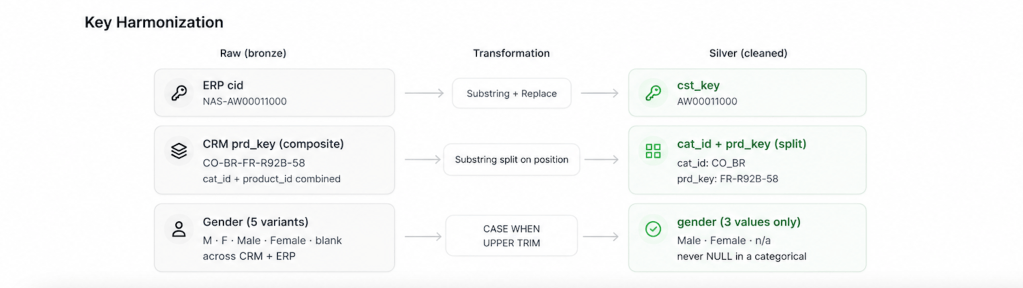
Gender was spelled five ways across two systems. The CRM stores M/F; the ERP stores some mix of M, F, MALE, FEMALE, blanks, and stray whitespace. Every fix runs through the same defensive sandwich — UPPER(TRIM(...)) first, then map:
CASE WHEN UPPER(TRIM(gen)) IN ('F','FEMALE') THEN 'Female' WHEN UPPER(TRIM(gen)) IN ('M','MALE') THEN 'Male' ELSE 'n/a'END
The ELSE 'n/a' matters more than the matches. I never let a blank or an unrecognized value become NULL in a categorical — NULL quietly drops rows out of GROUP BY counts and makes a dashboard lie by omission. 'n/a' is honest: it shows up, it’s countable, and it tells the analyst “we genuinely don’t know” instead of pretending the customer doesn’t exist.
Dates arrived as eight-digit integers. 20231215, stored as an INT. Some were 0. Some were the wrong length. The conversion has to refuse the bad ones rather than throw:
CASE WHEN sls_order_dt = 0 OR LEN(sls_order_dt) != 8 THEN NULL ELSE CAST(CAST(sls_order_dt AS VARCHAR(8)) AS DATE)END
Here NULL is the right answer — an unparseable date is genuinely unknown, and unlike a category it has no meaningful “n/a” bucket. Knowing when NULL is a lie (gender) and when it’s the truth (a broken date) is most of what data cleaning actually is.
The two systems didn’t agree on customer keys. The CRM’s clean cst_key had to line up against an ERP cid that came wrapped in noise — a NAS prefix on some rows, hyphens scattered through others. So Silver strips them down to a common shape: SUBSTRING(cid, 4, LEN(cid)) to drop the NAS, REPLACE(cid, '-', '') to kill the hyphens. The product key was a composite that needed splitting, not cleaning — its first five characters are a category code (REPLACE(SUBSTRING(prd_key,1,5),'-','_')) that joins to the ERP category table, while the remainder (SUBSTRING(prd_key, 7, ...)) is the actual product key that joins to sales. Half the work of integrating two systems is just discovering, the hard way, what each character of a “key” actually means.
Surrogate keys are generated in Gold, not carried from the source. Every dimension gets a clean integer key minted at view time:
ROW_NUMBER() OVER (ORDER BY cst_id) AS customer_key
This is deliberate. The fact table joins on these integers, never on the messy composite natural keys — so the BI model is fast and the source systems are free to renumber their own keys without breaking my schema. The natural keys stay in the dimension as attributes you can still filter on; they just stop being load-bearing.
What I built
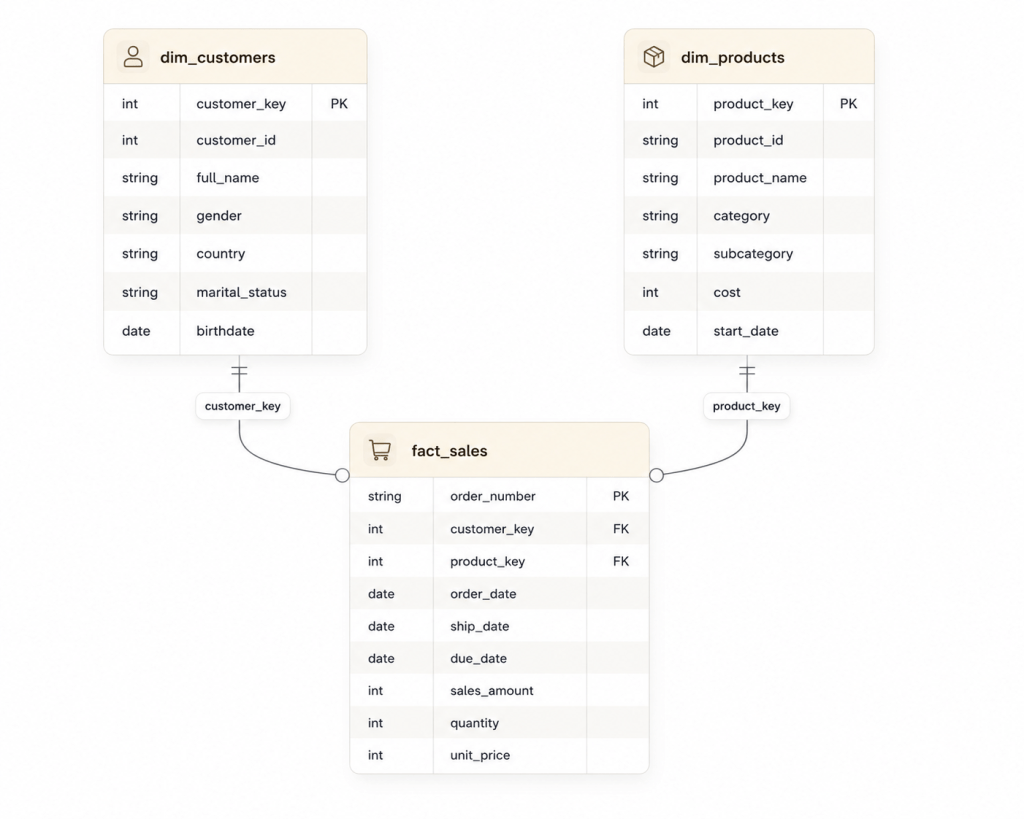
A three-table star schema, all exposed as Gold views:
dim_customersstitches the CRM customer master to two ERP modules (demographics oncst_key = cid, location on the same key) withLEFT JOINs, so a customer never disappears just because their ERP record is missing. Where the two systems disagree on gender, the CRM wins and the ERP only fills the gaps:
CASE WHEN ci.cst_gndr != 'n/a' THEN ci.cst_gndr ELSE COALESCE(ca.gen, 'n/a')
Picking an authoritative source per field — instead of blindly coalescing — is the difference between an integration and a guess.
dim_productsjoins the product master to the ERP category table and filtersWHERE prd_end_dt IS NULL, so the dimension holds only currently-active product versions. Surrogate key ordered by start date then key, for stable, reproducible numbering.fact_salessits at the grain of one row per sales-order line. ItLEFT JOINs both dimensions purely to translate natural keys into surrogate keys and keeps the order date as a degenerate dimension on the fact itself.
Then the part that makes it a warehouse and not just a query: quality checks as code. A test script per layer. The Gold checks assert the two invariants a star schema lives or dies on — surrogate-key uniqueness (GROUP BY ... HAVING COUNT(*) > 1 must return zero rows) and referential integrity (LEFT JOIN the fact to both dimensions, and any row where a key comes back NULL is an orphan fact — a sale pointing at a customer or product that doesn’t exist). If either query returns rows, the model is broken upstream and I want to know before an analyst does.
And the loads themselves are stored procedures — proc_load_bronze and proc_load_silver — so the pipeline is one repeatable call per layer, not a pile of ad-hoc scripts someone has to run in the right order from memory.
What this means in practice
For a data engineer: this is a clean, layered, idempotent pipeline you could hand to someone else on a Monday. Full-refresh loads mean no fragile incremental state to reconcile; the layer separation means a broken source file can’t silently corrupt a dimension; and the quality-check scripts are the regression suite — run them after every load and the schema tells you itself whether it’s sound.
For a business analyst: you query three tables that already agree with each other. Gender is always one of three values, dates are real dates, every sale joins to a real customer and a real product, and “current products only” is already handled. You don’t need to know the CRM exists, or that the ERP ever said NAS-AW00011000. That’s the entire point of Gold — the mess stopped at Silver.
Limitations and what I’d do next
I’d rather name these than have a reviewer find them.
Loads are full-refresh, not incremental. TRUNCATE + reload is perfect for a dataset this size and beautifully reproducible, but it won’t scale to billions of rows or sub-hour SLAs. The next step is incremental loads with change tracking and a watermark column.
The dimensions are Type 1 — they overwrite history. If a customer moves or a product is recategorized, the old value is gone. A real warehouse usually wants Type 2 slowly-changing dimensions on at least dim_customers, with effective-date ranges so historical facts join to the attributes that were true at the time of sale.
Quality checks run after the load, not during. They’ll catch a broken model, but only once it’s already built. I’d promote them to gating checks in an orchestrated pipeline so a failed assertion blocks the Gold refresh instead of just reporting on it.
No orchestration or scheduling yet. The procedures are the building blocks; the next move is wiring them into a scheduler (Azure Data Factory or similar) with logging, alerting, and dependency ordering so the whole thing runs and reports on itself.
Technical stack
Built entirely in T-SQL on Microsoft SQL Server / Azure SQL. Ingestion uses BULK INSERT from CSV; the Bronze and Silver loads are encapsulated as stored procedures for repeatable, single-call execution. Transformations lean on standard SQL — CASE/UPPER/TRIM for cleansing, SUBSTRING/REPLACE for key harmonization, and ROW_NUMBER() window functions for surrogate-key generation. The Gold star schema is delivered as CREATE VIEW definitions so it always reflects current Silver data, and the quality assurance lives in standalone test scripts versioned alongside the DDL in Git.
